Service360 setup
Get started with Service360

Service360 concepts
Service360 is centered around custom in-house built digital assets - Services.
One of the main ideas of Service 360 is that operational service documentation MUST be collocated with the code. Documentation needed for the maintenance of the service MUST be committed to the same repository as the Service code.
Service360 does NOT provide any write interface for maintenance of service documentation. All the needed changes should be done directly in the service repository and follow usual code-review practices as the usual code. That way we increase chances that documentation not only will stay up-to-date, but also will be as concise as possible (engineers rarely like to write huge docs).
Services are grouped into Libraries. Libraries do belong to one Organization
and are composed out of multiple Sources (git repositories/organizations).
And Sources have multiple Plugins configurations assigned to them.
Organization
If you want to use Service360 you must create or join an Organization at
https://admin.service360.io.
Organization is used to group together organisation assets (services,
libraries, teams) and manage access of users to those assets.
Organization is identified by the name and the slug which are given
during the organization registration and can not be changed later.
Access to the organisation assets is managed on the organisation level. It means that users who do have access to one organisation library will also have access to all.
There are only two types of access privileges - Admin and Viewer:
- Admin users can manage all settings of the organization
- Viewers have access only to Service360 frontend

Organization settings

Users access management
Library
From the Viewer user perspective Library is a way to group together Services,
TechRadar, Contributors ,Library risks and such.
From the Admin user perspective Library consists of two main elements:
- collection of
Sources TechRadarsetup
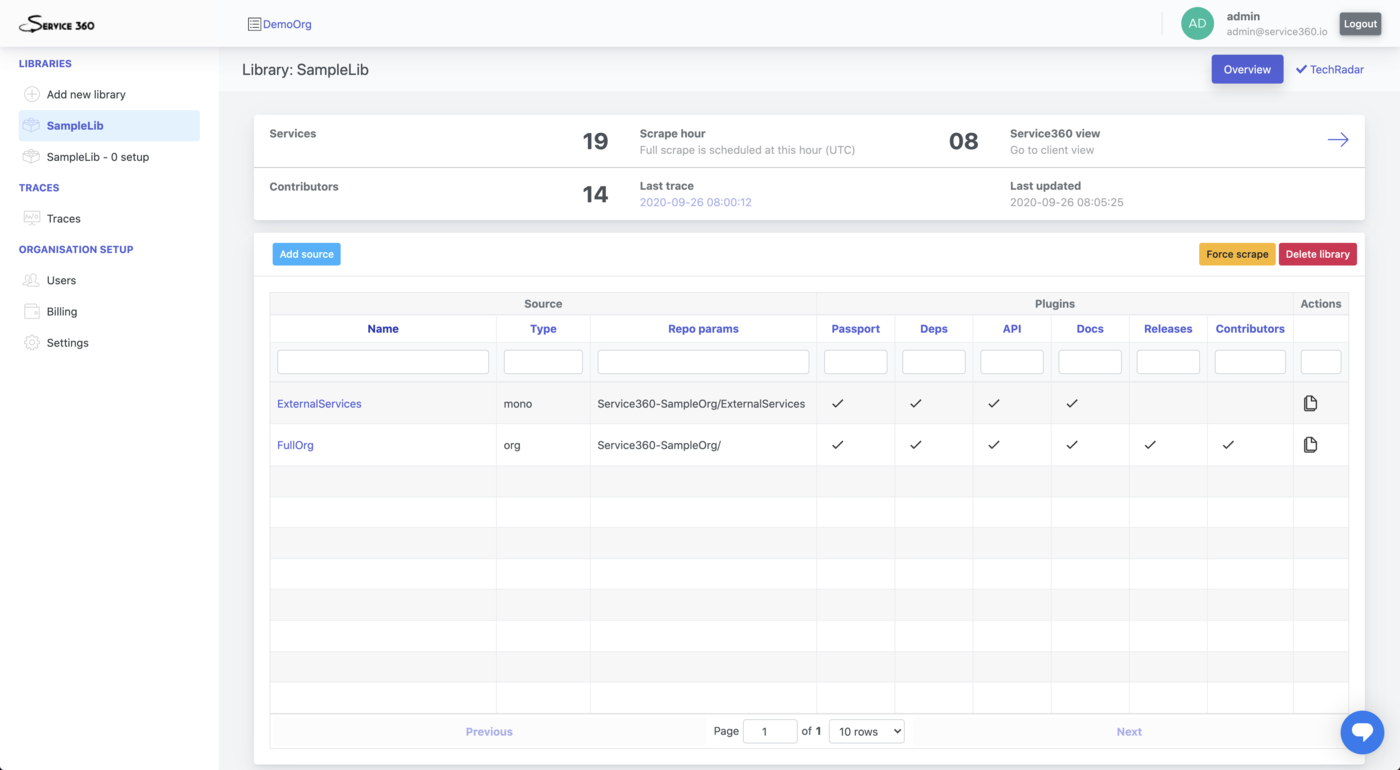
Sources list
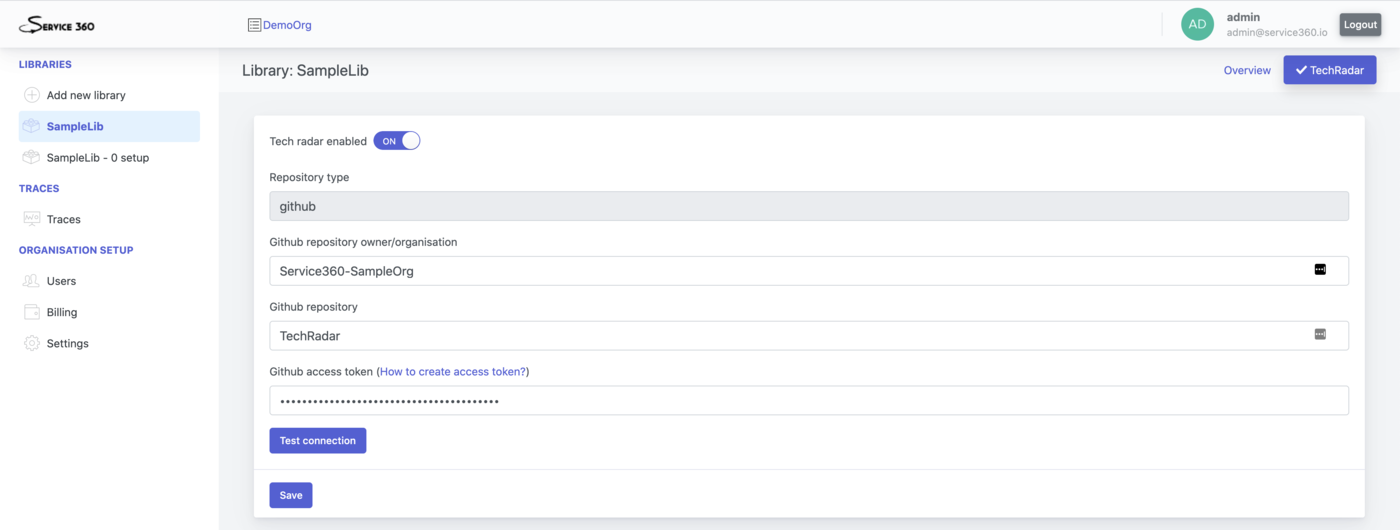
Tech radar setup
Source
Source is way to tell Service360 from where it should get information
about Services.
Service360 currently supports 3 types of sources:
- Github organisation
- Github single repo (repository holds tha data about one service)
- Github monorepo (repository holds the data about multiple services in different folders)
For all types of sources you would need to provide a Github access token to grant Service360 access to your repositories. You can check how to create access token in the official github documentation. Service360 requires only read-only access to the repositories.
We advise to create a separate user for Service360 and give it limited rights to the repos you want to crawl. Separate user is preferred against using your personal token because of Github quotas. Github quotas work on the user, not token, level. In case you have a lot of repositories which must be crawled by Service360 it might happen that user access to Github API will be rate-limited.
Service360 respects Github API Fair Use policy and crawls Github in one thread only. This might lead to quite long time for initial crawling. For example crawling of ~500 repos takes approximately 3-4 hours.
If you just start with Service360 we recommend to use “Github organisation”
source type. In this crawling mode all the Service360 treats every repository
of the github organization as a separate Service.
In case you have some repositories which actually hold multiple Services -
use Github monorepo source type.
And if you want to have super fine-grained control over the contents of your
library you can create as many of Github single repo sources inside of one
library as you want.
Common pattern for Service360 setup is to add full organisation as a source and blacklist all monorepos which exist there. And add Monorepos as a separate source.
Repository inside of the library is the billing entity. You will be billed
proportionally to the amount of scanned repositories in each
Library.
Service360 rescans all Libraries once per day. In case need be each organisation has two additional “force” crawls which can be triggered from the admin interface.
Source setup
Plugins
There is a lot of information that can be retrieved from the git repository.
Plugins are responsible for that.
Currently Service360 support 6 types of Plugins:
- Passport
- Service Dependency Graph
- Docs
- API
- Releases
- Contributors
Each of the plugins is responsible for the collection of different set of data
from the Source. While all of the plugins have very sensible defaults settings,
you still can reconfigure some behaviours.
Passport
The only Plugin which can not be turned off. Passport plugin is responsible for gathering the information from the Service Passport.
By default Service360 searches for the properly formatted passport in the README.md
file in the root folder of the repository. You can reconfigure what filename should be
checked and it is location by adjusting Folder and Filename options.
For the Mono repository Folder option is used to point to the folder which contains
folders with your applications.
Data collected by this plugin powers “ServiceRegistry” and “Tech” perspectives and detection of various types of risks.
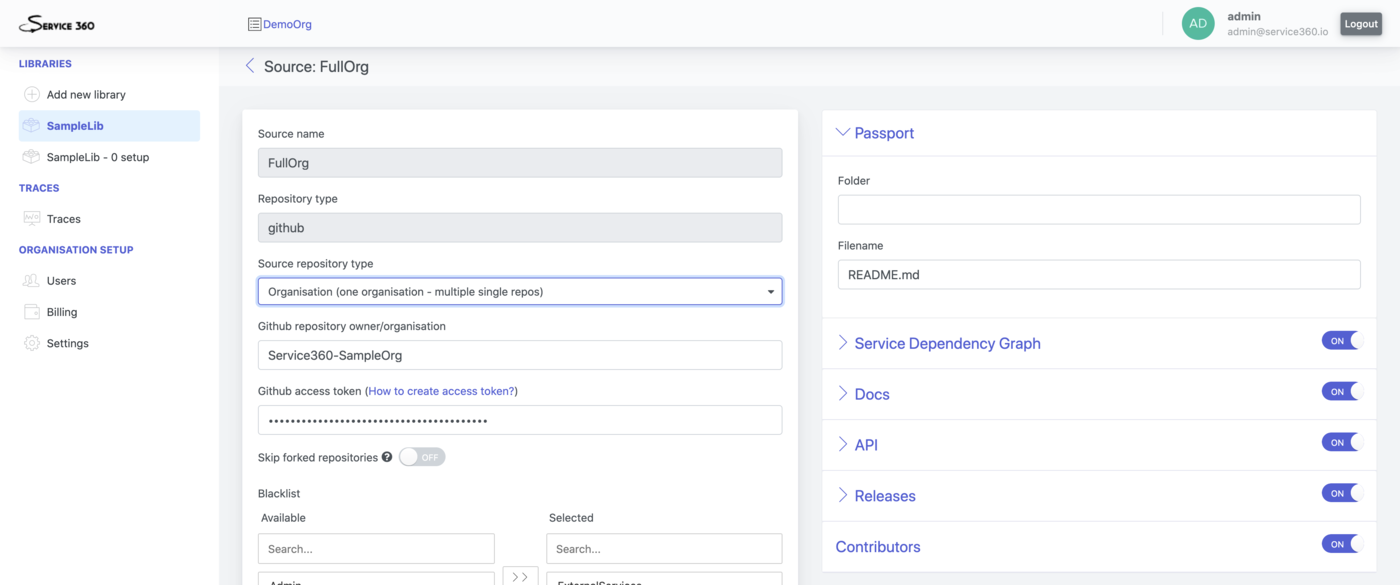
Passport setup
Service Dependency Graph
This plugin is responsible for parsing “Service Dependency Graph” files.
By default Service360 searches for the properly formatted dependency file in the deps.s360.puml
file in the root folder of the repository. You can reconfigure what filename should be
checked and it is location by adjusting Folder and Filename options.
Data gathered by this plugin is used to power “BigPicture” perspective, service dependency detection and various types of dependency risk detection.
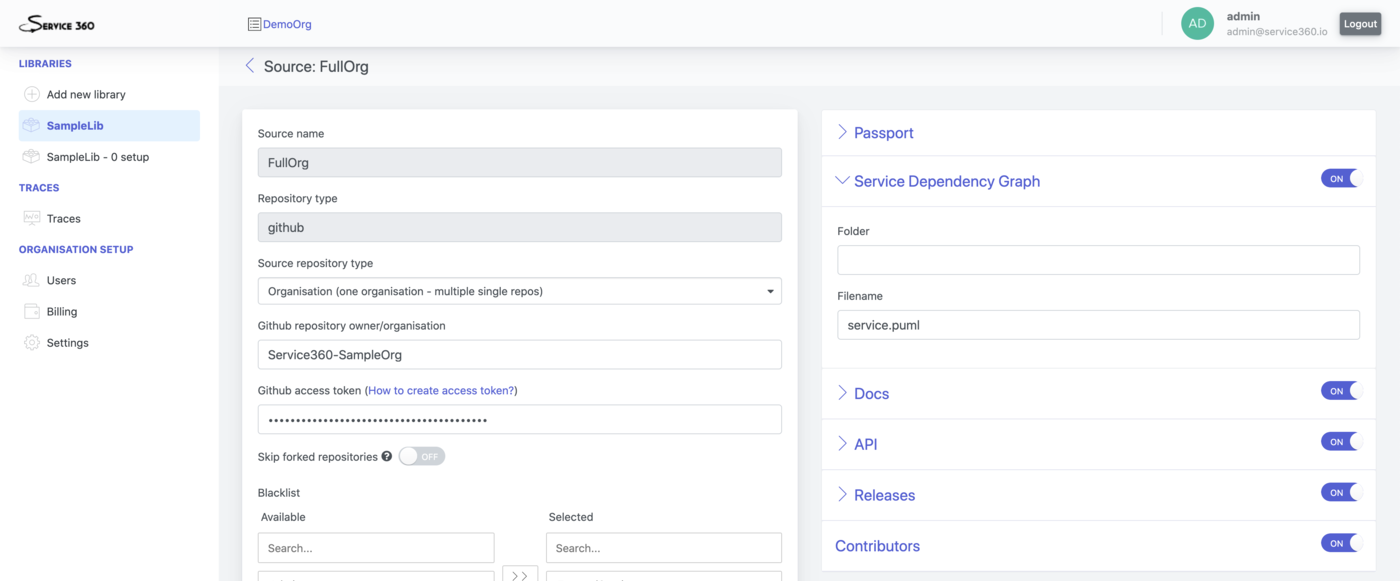
Service Dependency Graph setup
Docs
This plugin is responsible for retrieving service documentation from the repository. It downloads all *.md, *.png, *.jpg/jpeg files to make them available through Service360 interface. No assumptions are made on the structure or the contents of the downloaded files at the time of downloading.
Later Service360 checks if the downloaded content fits to the DevOps Service Docs standard and raises some alerts in case some recommended documentation is missing.
By default Service360 scans everything in the docs folder of the repository.
You can reconfigure the folder name by adjusting Folder option.
Data collected by this plugin powers “Docs” section of the “ServiceRegistry” Service page and detection of various types of risks.
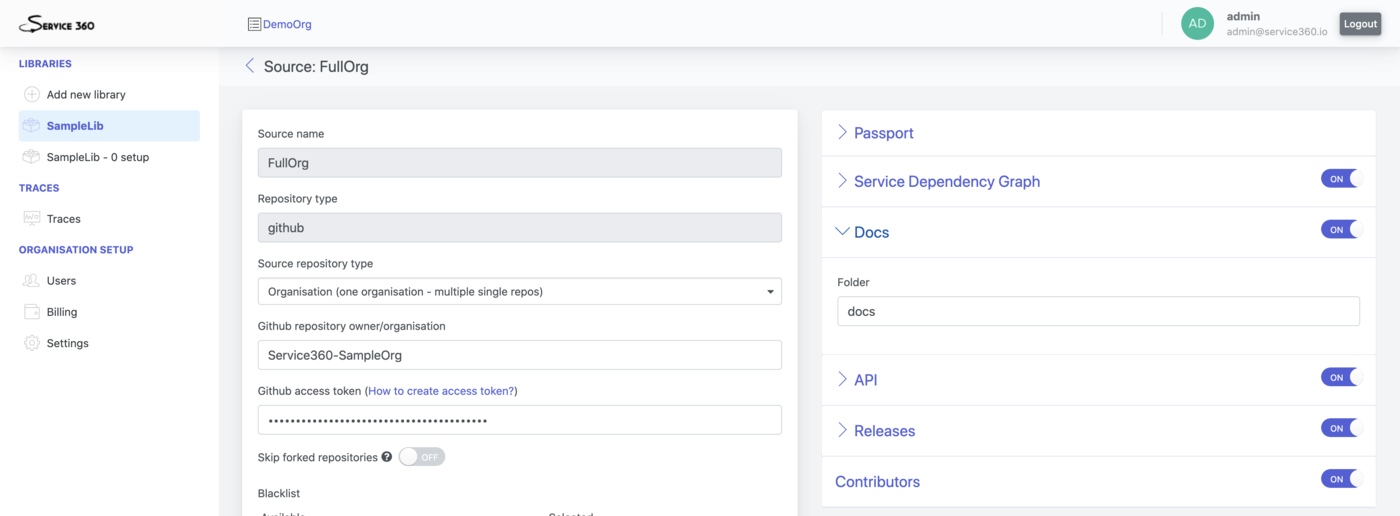
Docs setup
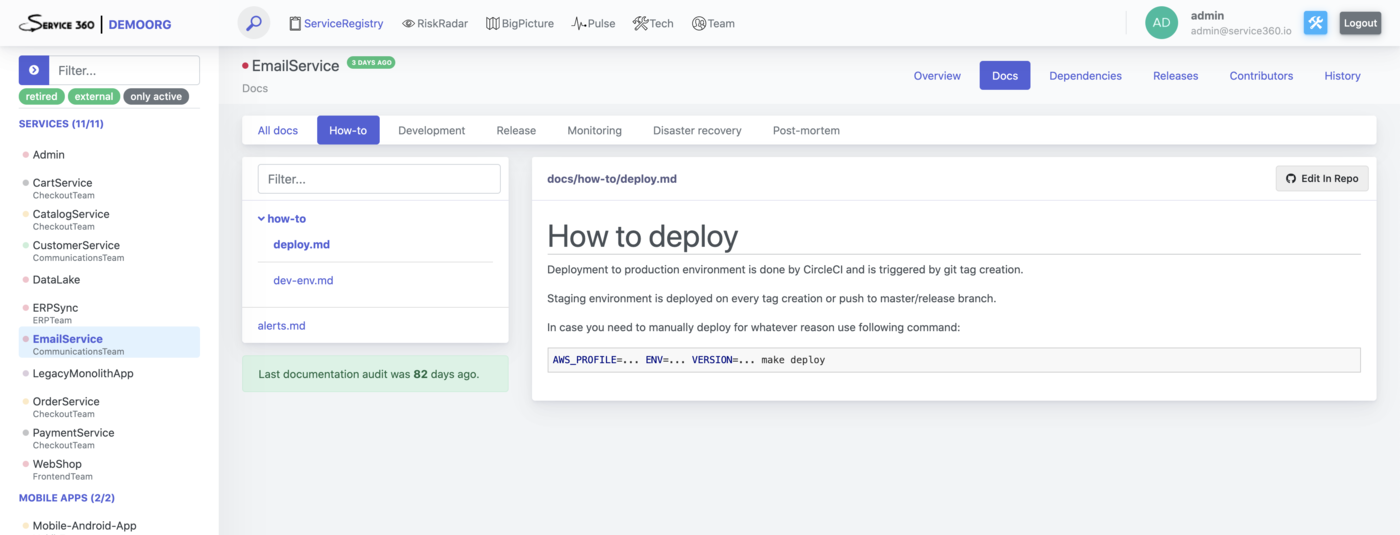
Docs section of the Service page
API
This plugin is responsible for retrieving OpenAPI/Swagger description of the service API from the repository. If the file is present and is correctly formatted as OpenAPI document it will be downloaded and exposed via Service360 interface.
By default Service360 searches for the properly formatted file in the openapi.yaml
file in the docs/api folder of the repository. You can reconfigure what filename should be
checked and it is location by adjusting Folder and Filename options.
Data collected by this plugin powers “API” section of the “ServiceRegistry” Service page.
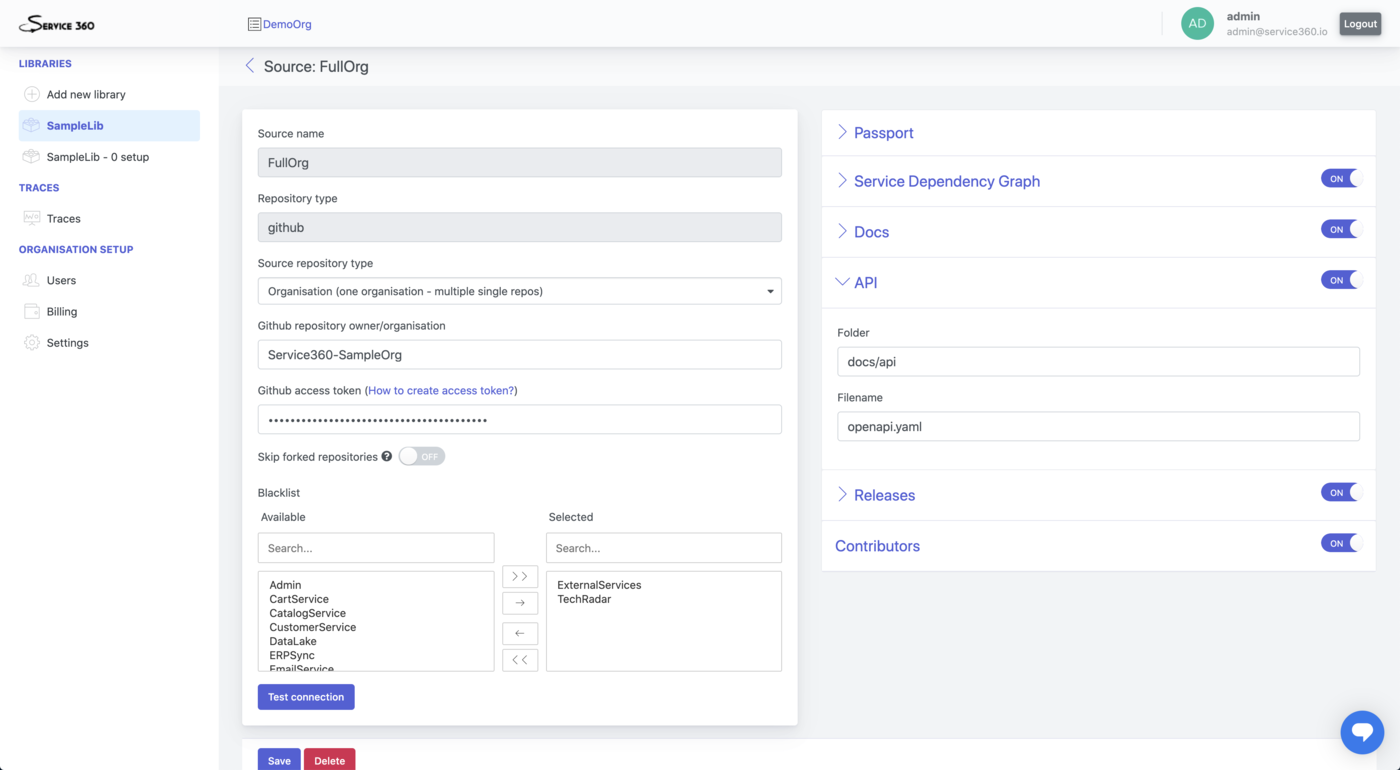
API setup
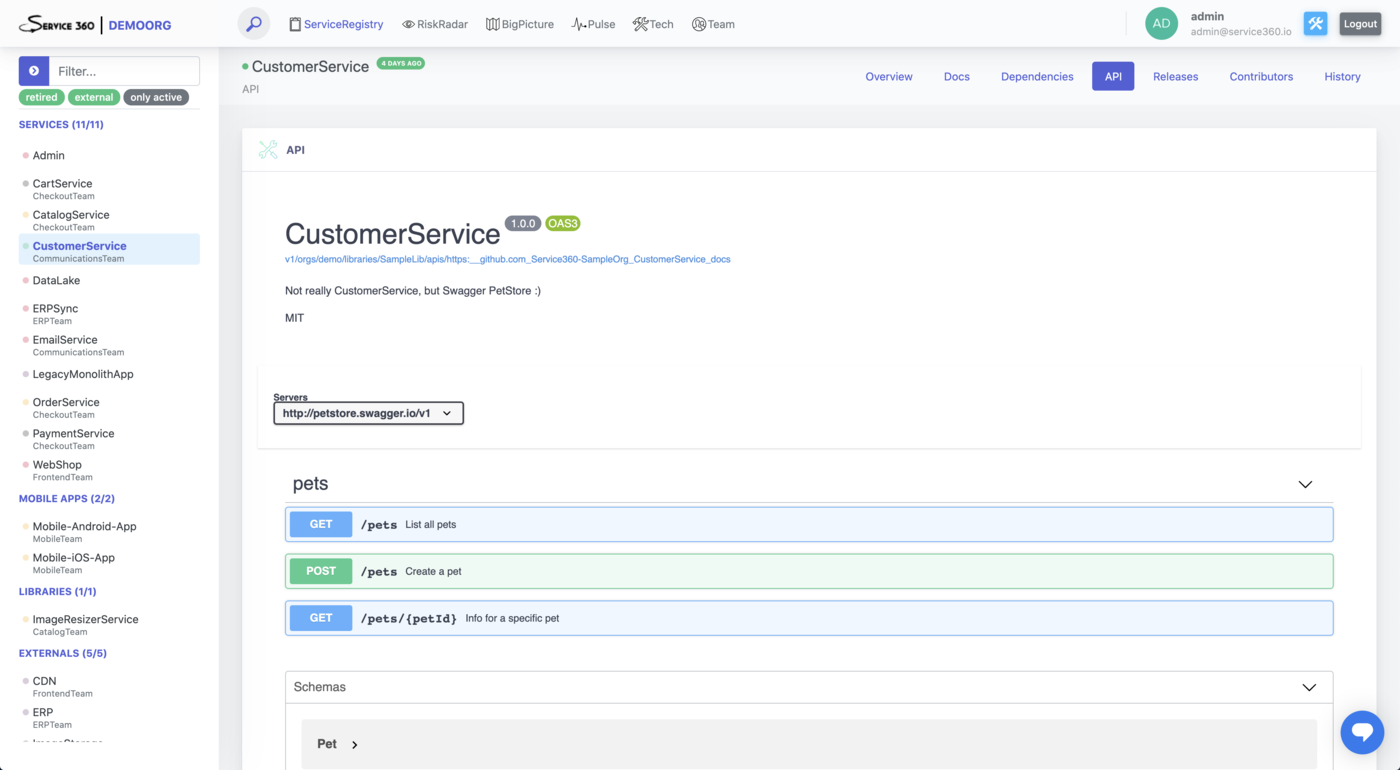
API section of the Service page
Releases
This plugin is responsible for collecting releases/deployments of the service.
Currently Service360 supports two ways of release detection:
- Each Github release is treated as an application release
- Each direct commit (or merged PR) to master is an application release
Choose the mode which suits better for your deployment flow.
Data collected by this plugin powers “Pulse” perspective, “Releases” section of the “ServiceRegistry” Service page, and detection of various types of risks.
Releases setup
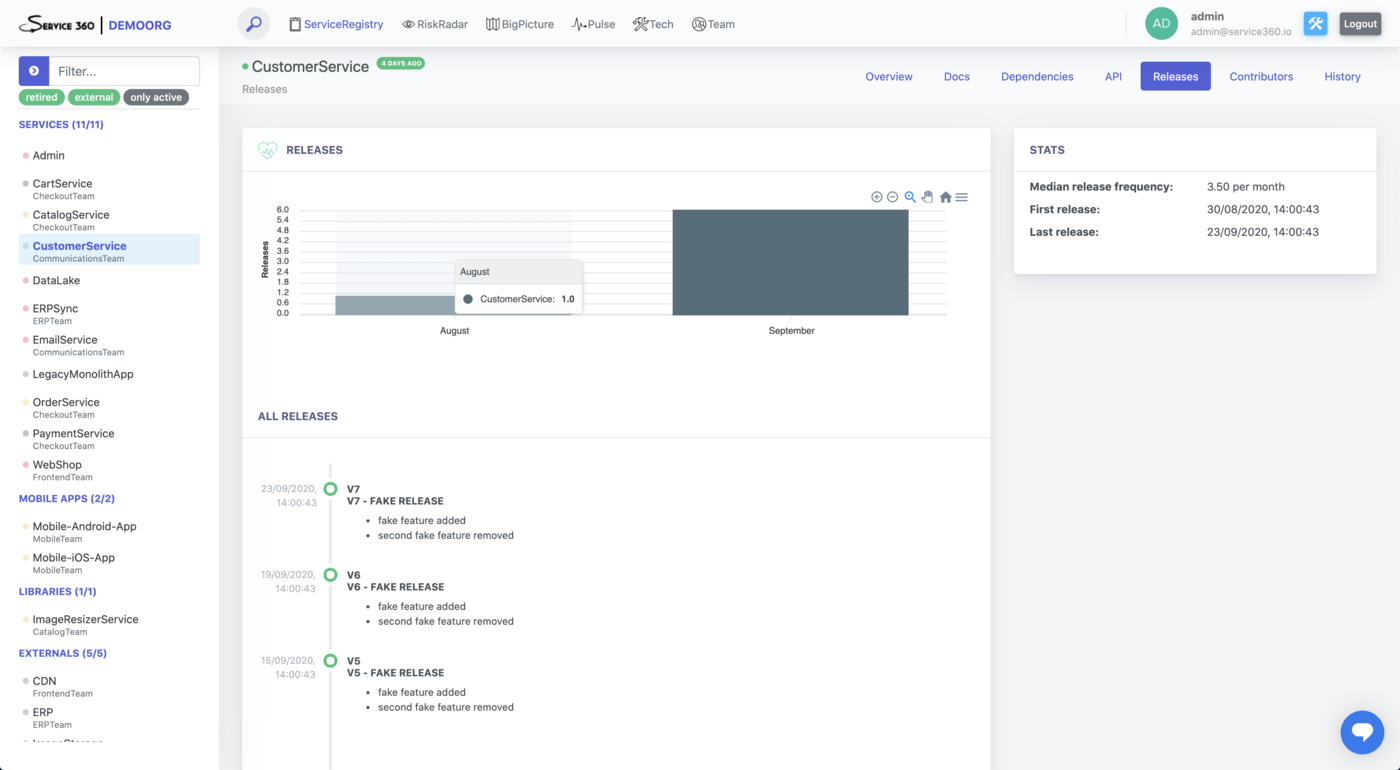
Releases section of the Service page
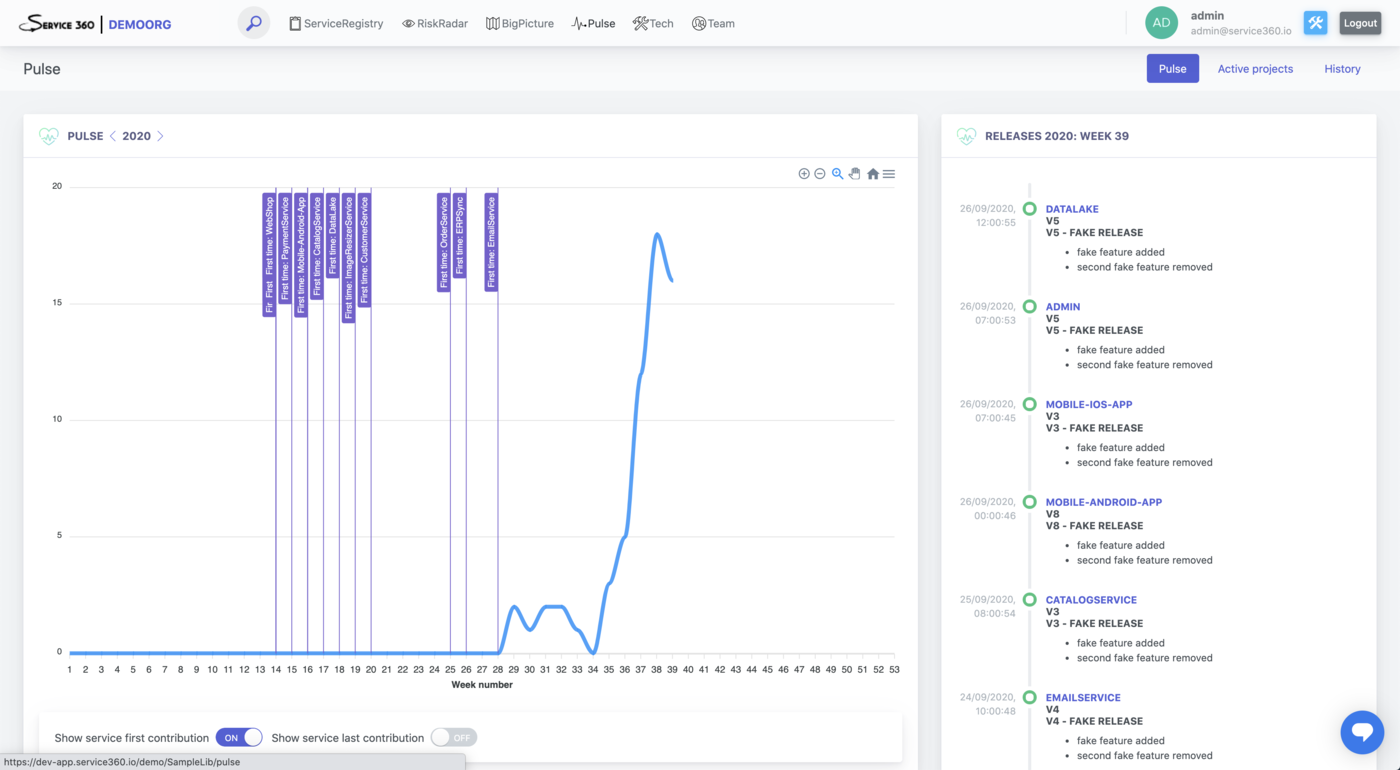
Pulse perspective
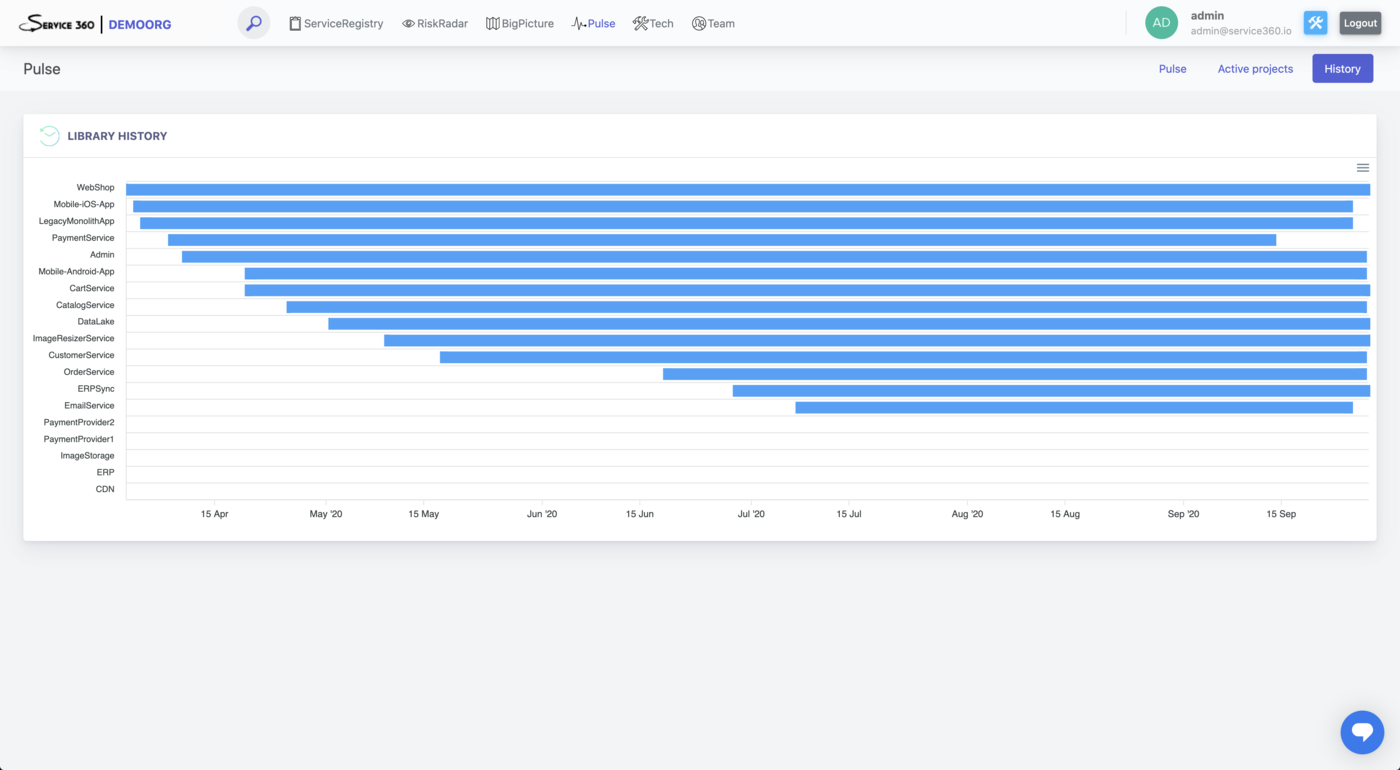
Library history page
Contributors
Contributors plugin collects data about contributors and theirs contributions to the service.
Data collected by this plugin powers “Team” perspective, “Contributors” section of the ServiceRegistry service page, lots of different Service insights (SME, Tech expert Available in Alpha, and such), and is used for the human/team-related risk assessment.
Due to the way data collection is implemented (not really parsing your repositories but using Github API instead) it might happen that you will not see some contributors which you would expect to see. This happens than Github is not able to detect a github account of the contributor due to changed email, for example. This is a known limitation and we looking for the ways to work it around.
In case of mono repositories it is advised to disable the Contributors plugin for the mono repo setup, but instead also add mono repository as a single repository type source and enable Contributors plugin there. That way you will have correctly calculated contributions.

Contributors setup
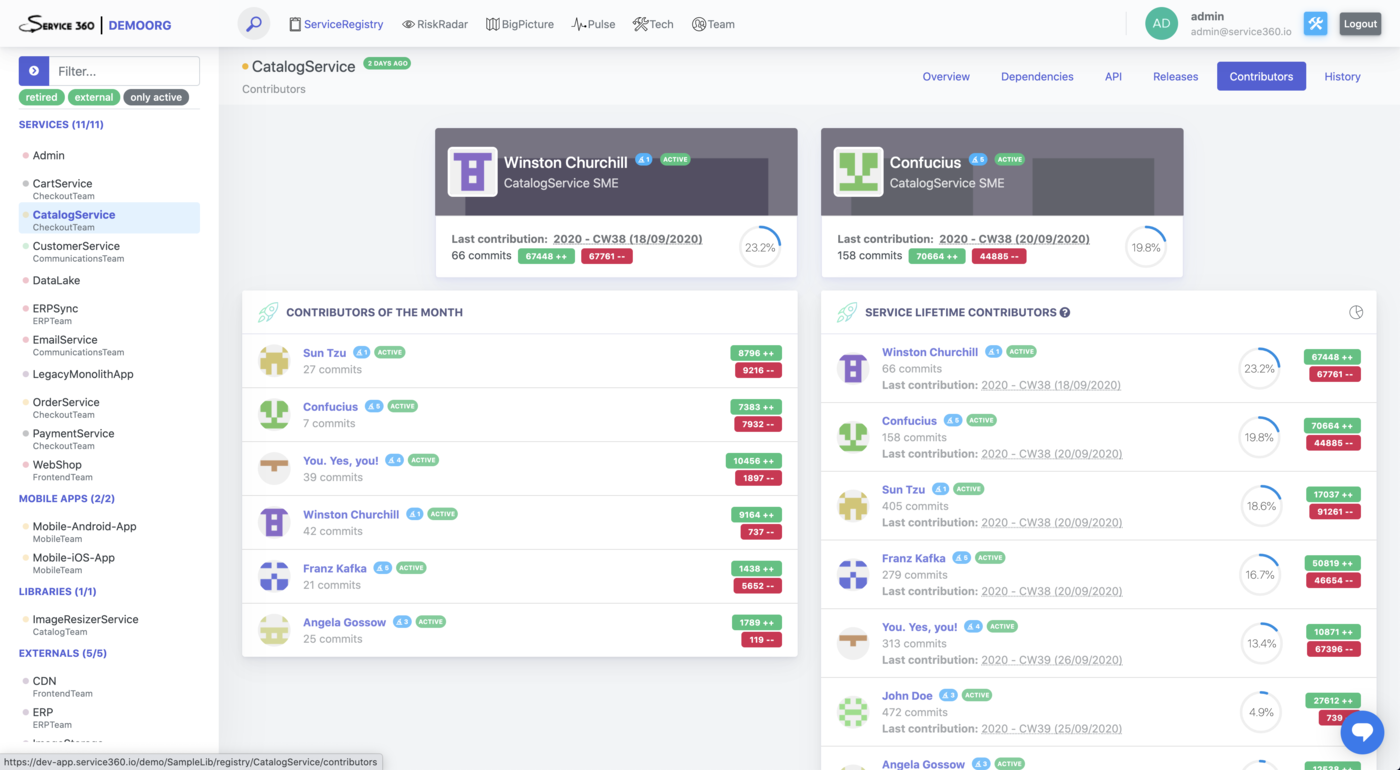
Contributors section of the Service page

Team perspective
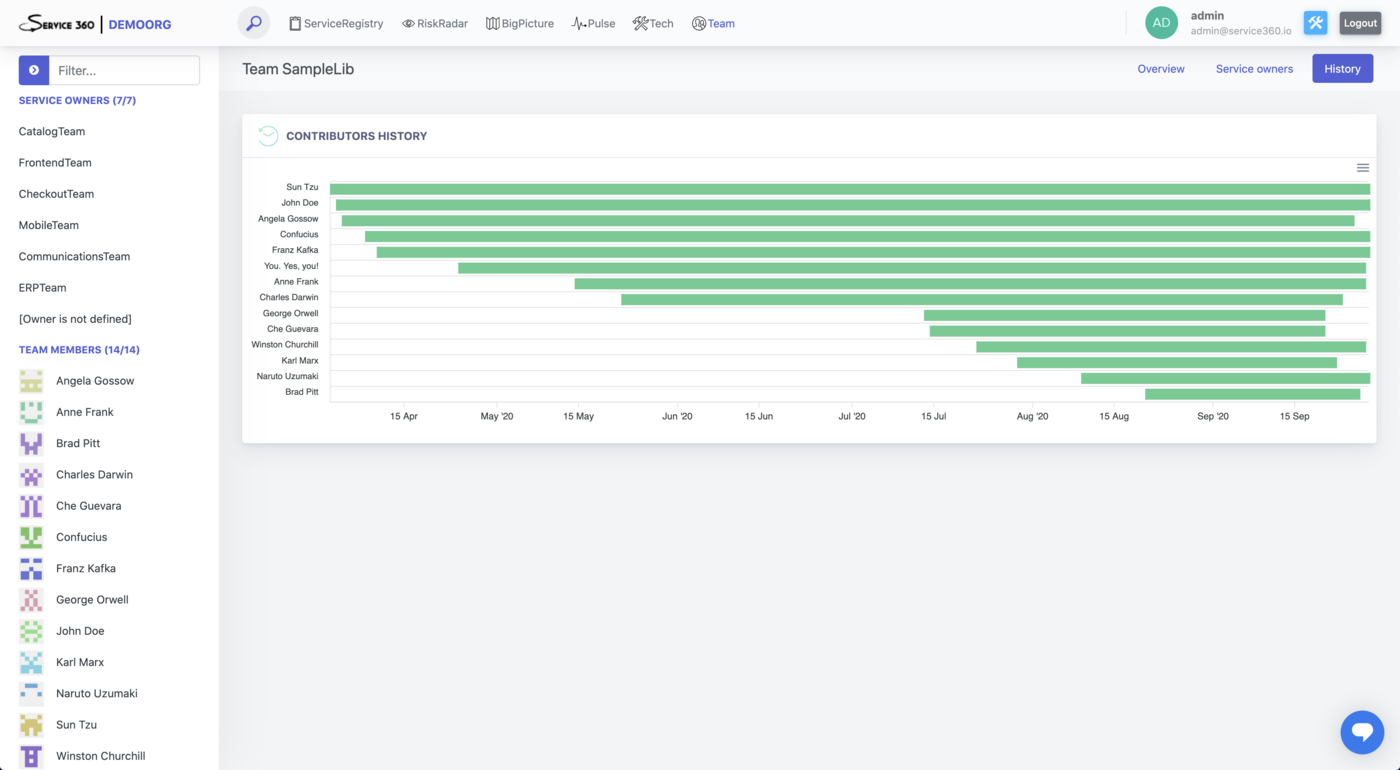
Team history page
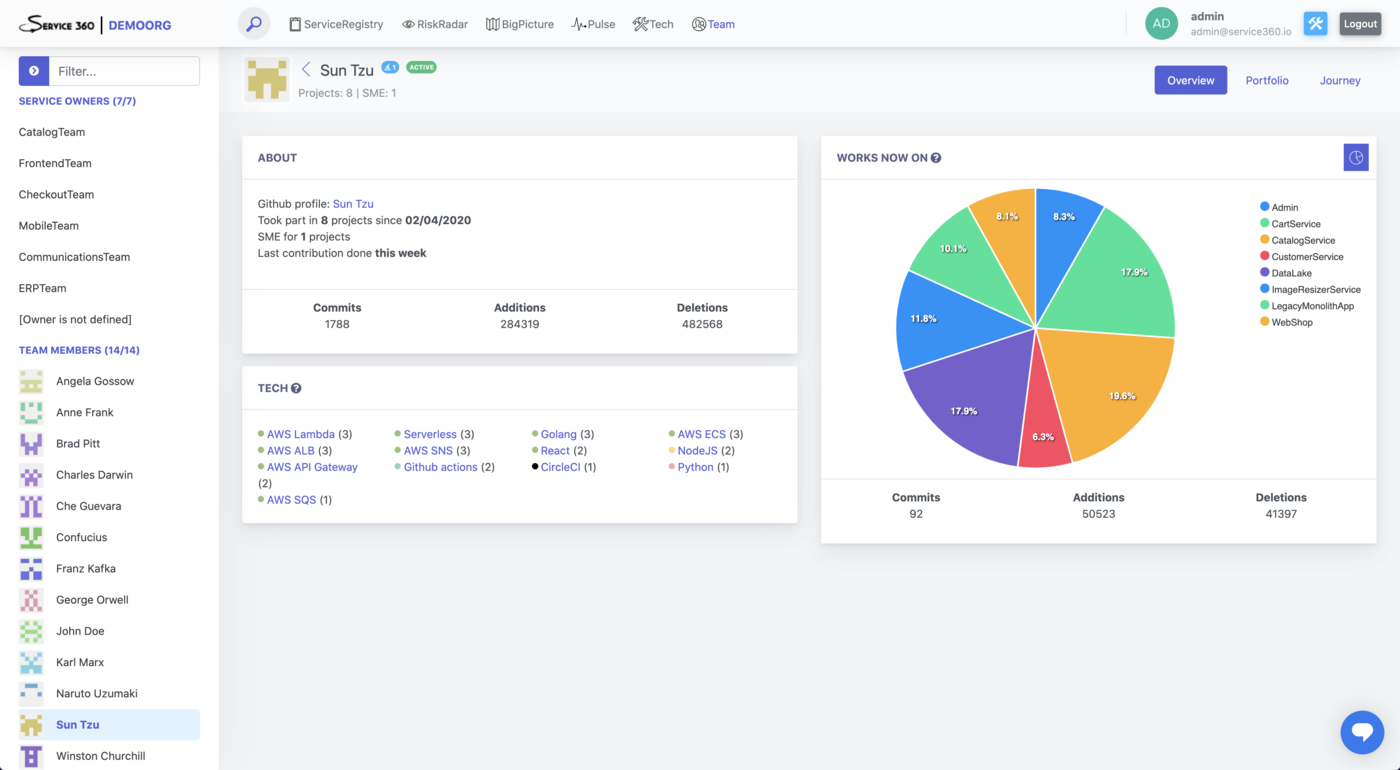
Contributor profile
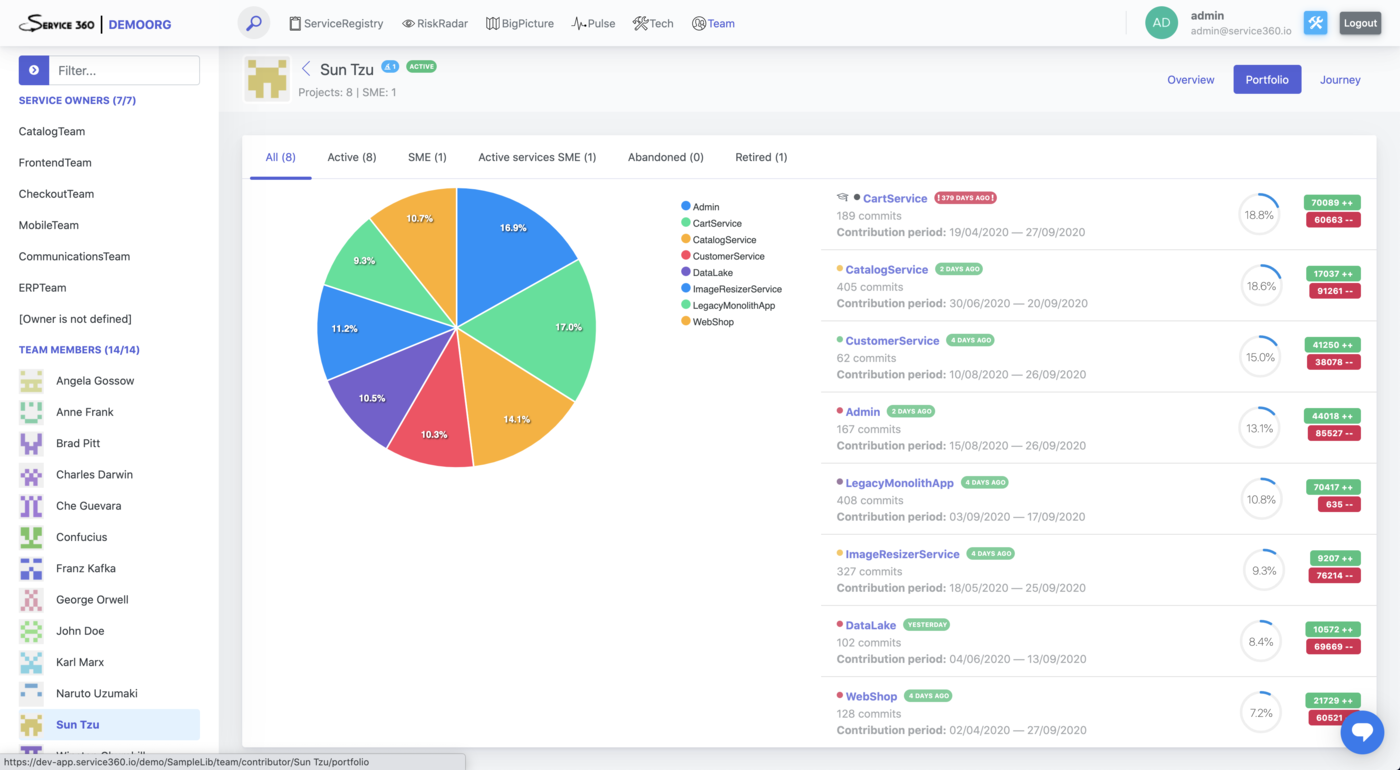
Contributor portfolio
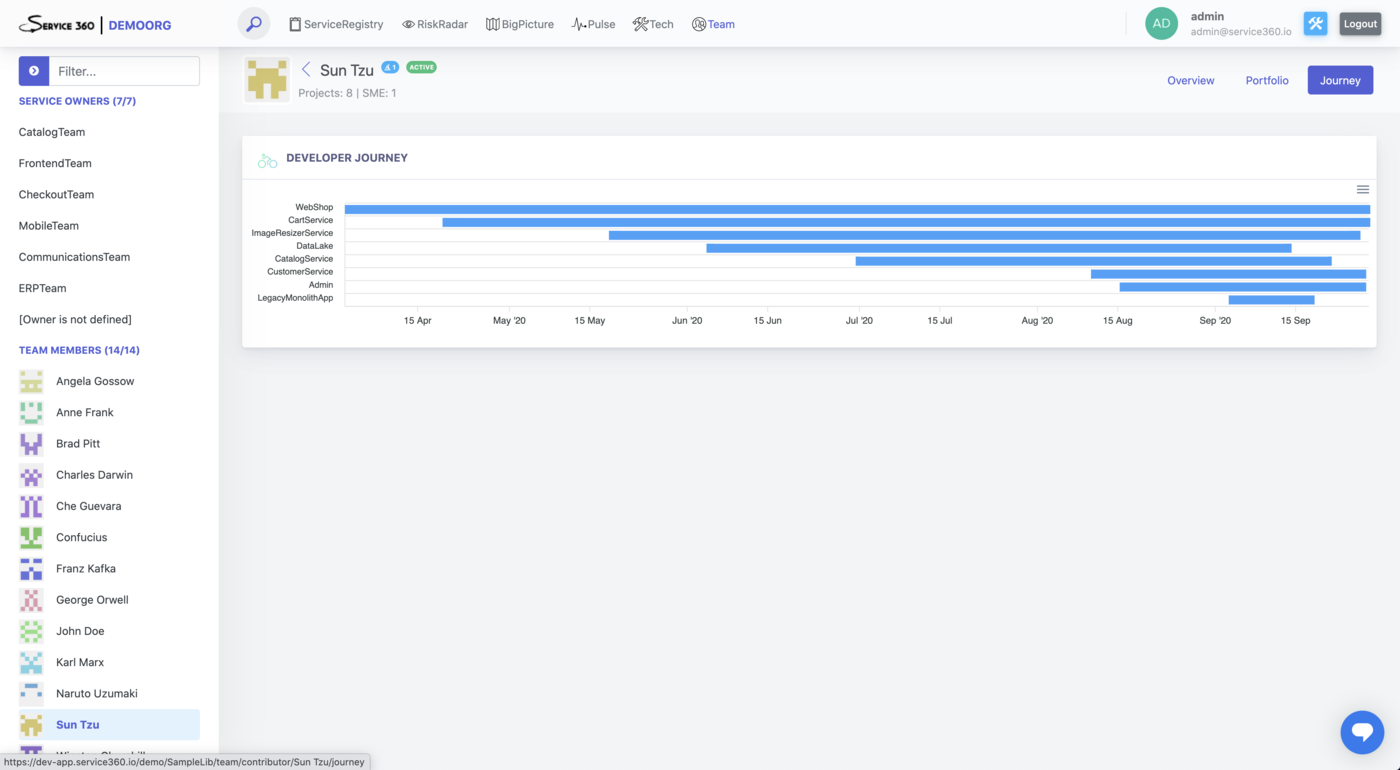
Contributor history
TechRadar setup
TechRadar section of the library setup is responsible for configuration of the dedicated TechRadar repository.
Setup is pretty much the same as the setup of the Single repo Source with the exception that there is no need to configure any plugins.
Data collected by the TechRadar is used to power the “Tech” perspective of Service360.
TechRadar setup

Full fledged tech radar overview
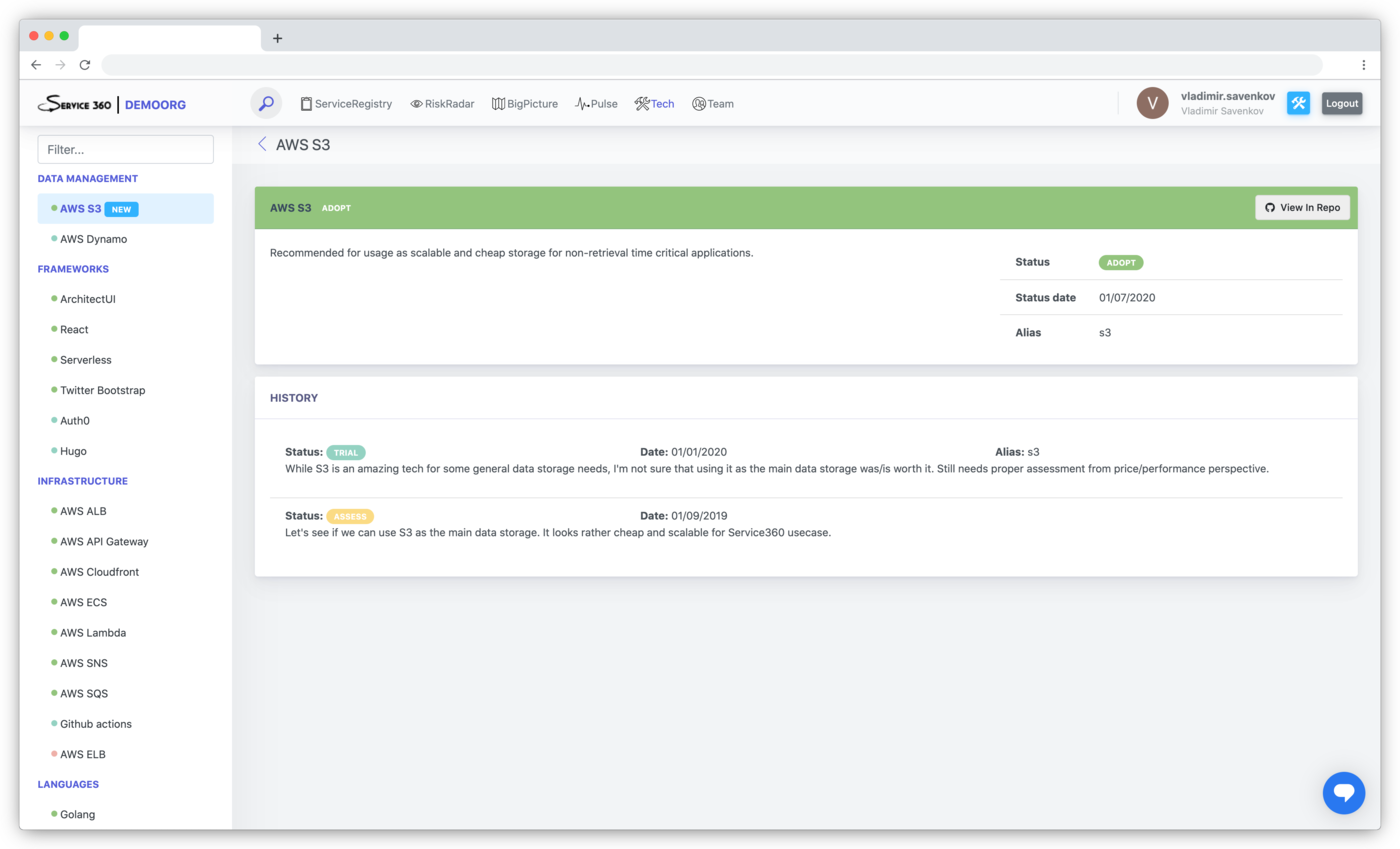
Example of the technology page
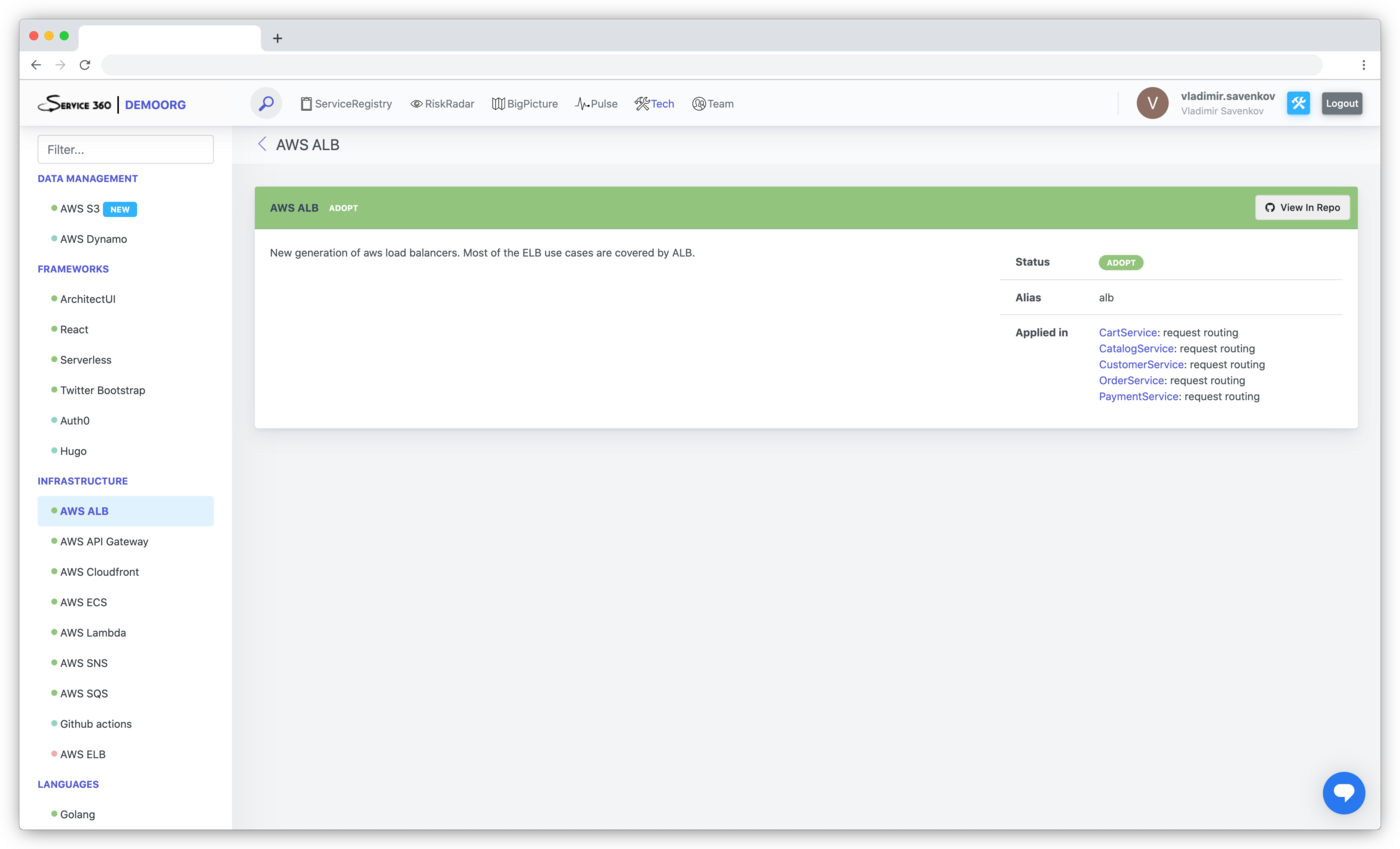
Example of the technology page with applications
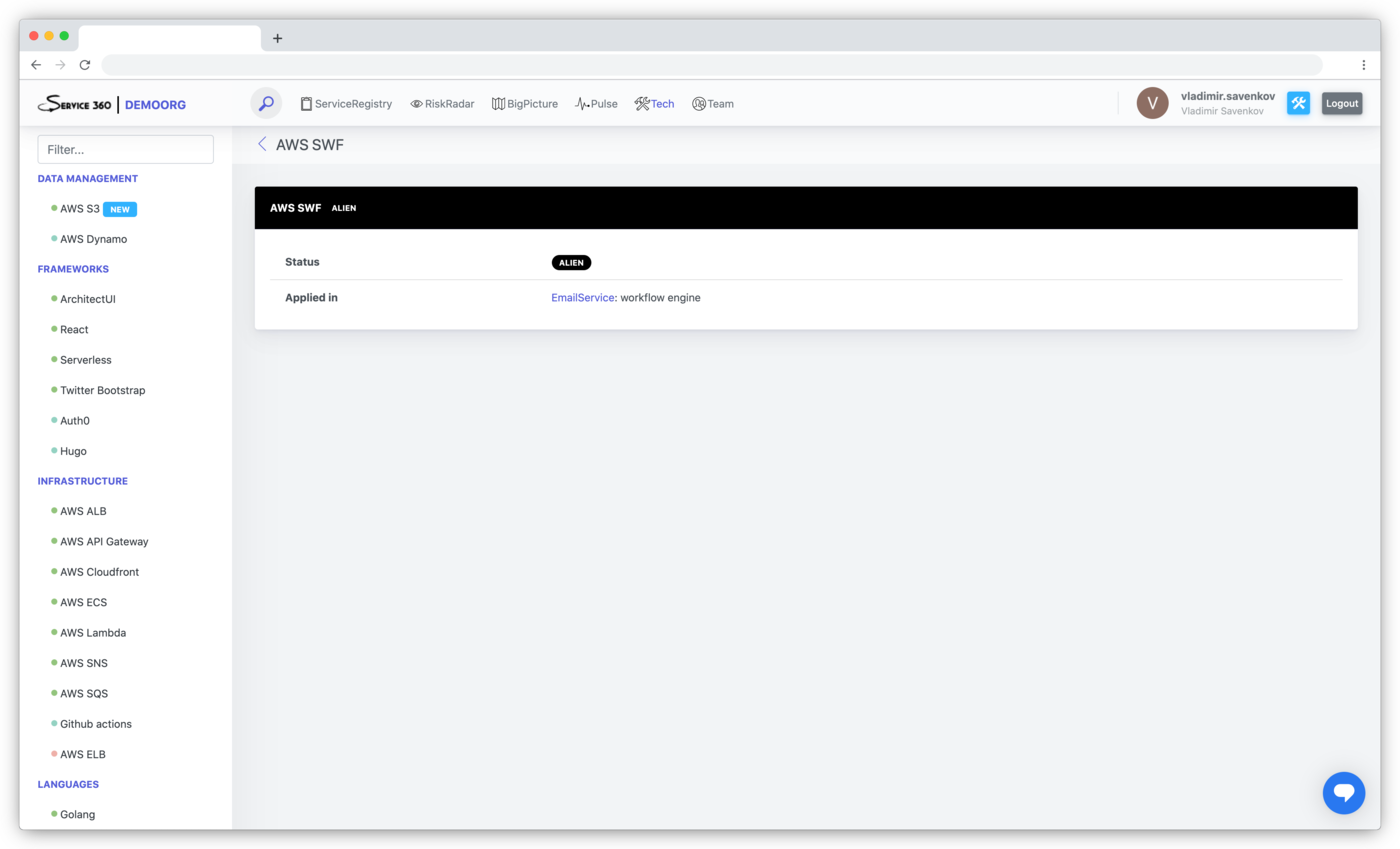
Alien technology detection (technology not specified in the tech radar, but is used by some service)
Very soon
We are working hard with our alpha testers to make sure you will get the best in class product. Subscribe to our newsletter to stay informed about the progress and to receive an invitation to our beta test!